腾讯混元 T1 正式版发布
腾讯混元 T1 正式版发布
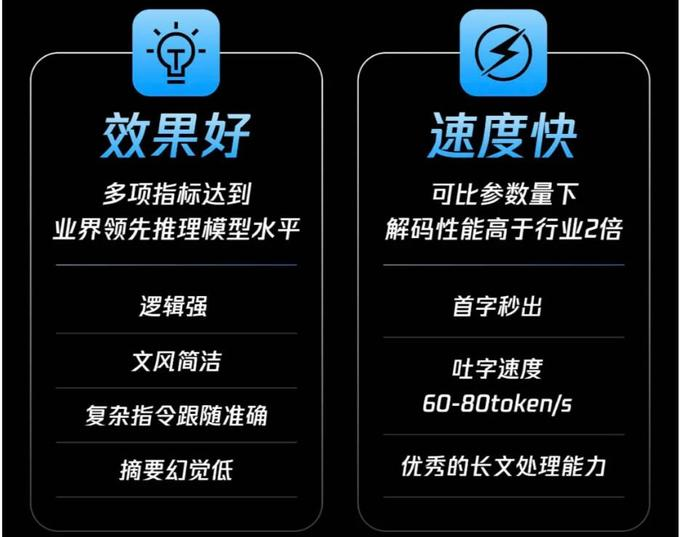
2025 年 3 月 21 日,腾讯正式推出自研深度思考模型混元 T1 正式版。这款基于 Hybrid-Mamba-Transformer 融合架构的推理大模型,不仅以“首字秒出、吐字速度 60-80 tokens/s”刷新行业效率标杆,更在数学、逻辑推理等硬核领域展现了逼近人类专家的能力。其发布标志着大模型技术从“通用能力竞赛”迈入“垂直场景效能革命”的新阶段。架构创新 传统大模型受限于 Transformer 架构的

2025 年 3 月 21 日,腾讯正式推出自研深度思考模型混元 T1 正式版。这款基于 Hybrid-Mamba-Transformer 融合架构的推理大模型,不仅以“首字秒出、吐字速度 60-80 tokens/s”刷新行业效率标杆,更在数学、逻辑推理等硬核领域展现了逼近人类专家的能力。其发布标志着大模型技术从“通用能力竞赛”迈入“垂直场景效能革命”的新阶段。
架构创新
传统大模型受限于 Transformer 架构的计算复杂度,面临“提升性能必增成本”的困境。混元 T1 采用的 Hybrid-Mamba-Transformer 融合架构,通过三大技术创新打破僵局:
- Mamba 组件专攻长序列:针对数学证明、代码分析等需要长距离依赖的场景,以普通 Transformer 1/5 的计算量维持信息连贯性,解决长文本推理中的“上下文丢失”顽疾。
- 动态路由的 MoE 系统:自动激活特定任务专家模块(如代码、数学单元),在保持 32k 上下文窗口的同时,将解码速度提升 2 倍。
- 内存优化设计:通过降低 KV-Cache 内存占用,使单次训练成本下降 40%,推理能耗仅为同类模型的 60%。
这一架构让混元 T1 在保持顶级性能的同时,输入定价低至 1 元/百万 tokens,输出价格仅 4 元,创行业成本新低。

性能突破
混元 T1 的专项优化策略使其在硬核推理领域得到提升:
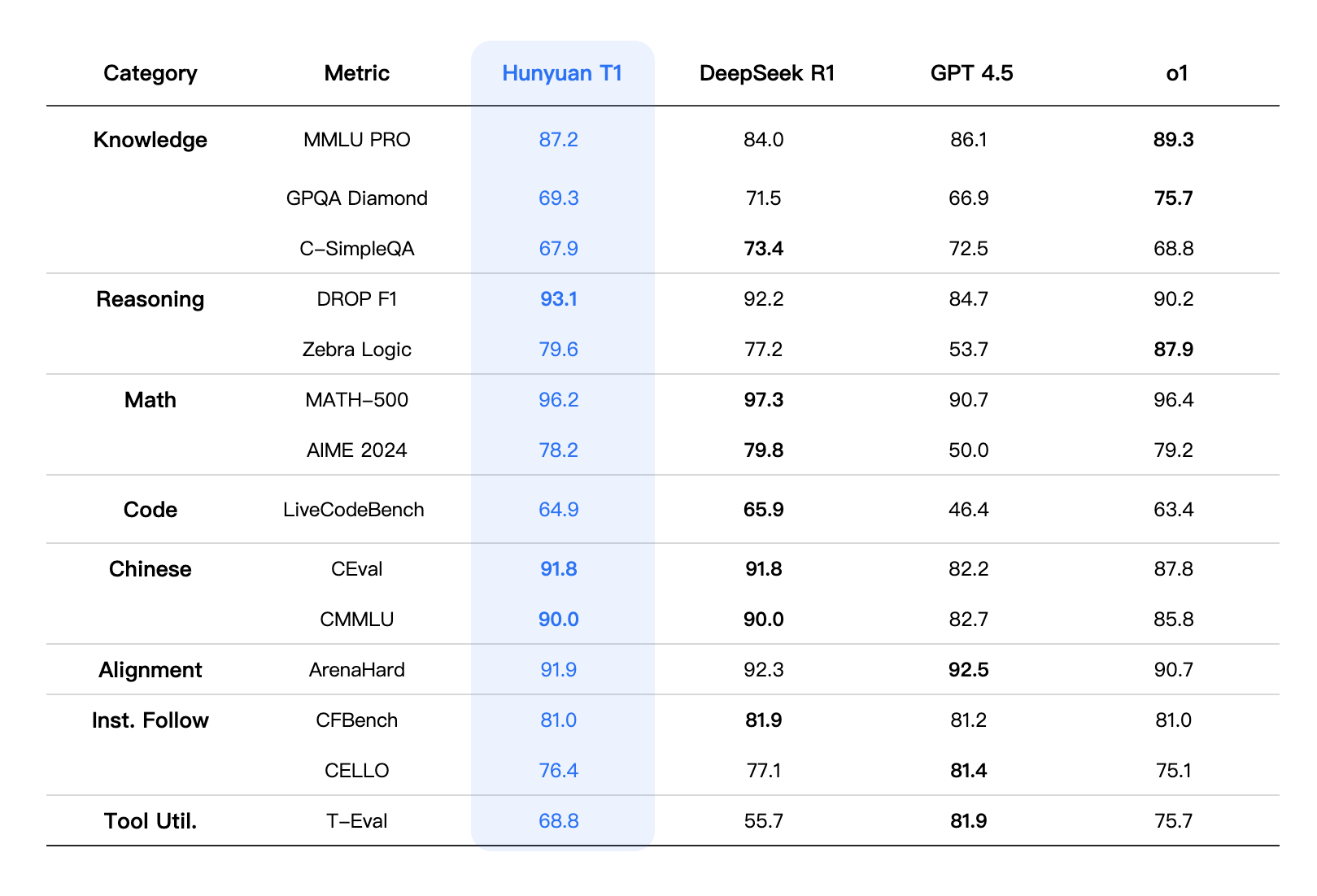
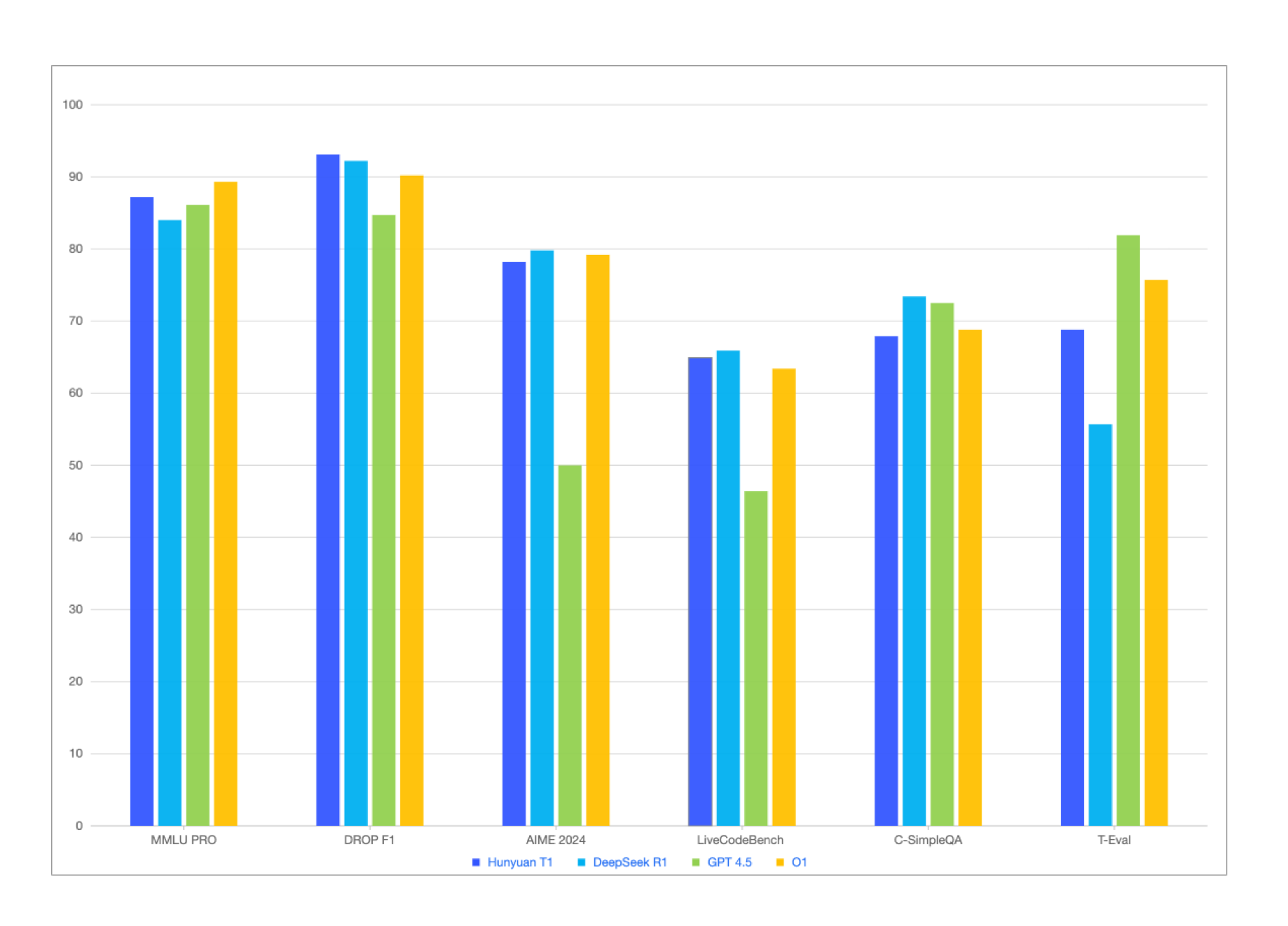
- 数学能力:在 MATH-500 评测中取得 96.2 分,可解包含 10 步以上推导的奥数难题,与 DeepSeek R1、O1 形成“三足鼎立”。
- 代码场景:LiveCodeBench 评测 64.9 分,超越 O1 的代码生成质量,尤其在动态调试建议方面展现独特优势。
- 批判性思维:能够识别用户提问中的逻辑矛盾(如自相矛盾的快递违禁品询问),并主动进行多视角分析,这在快递 100 智能体的实际应用中已得到验证。
特别值得关注的是其中文能力——在 CEval 中文基准测试中,其表现大幅超越 GPT-4.5,与 DeepSeek R1 持平,打破了“英文模型更强”的固有认知。
行业落地
混元 T1 的技术突破正在转化为实际商业价值:
- 物流智能化:在腾讯元宝平台,快递 100 智能体通过接入 T1 实现了三大升级:
- 隐性需求洞察:当用户询问“寄荔枝是否易坏”时,能自动关联保鲜方案建议而非简单回答合规性。
- 跨平台比价:整合 2100 家快递公司数据,提供运费智能推荐。
- 风险预警:识别用户诱导性提问(如故意将荔枝归为违禁品),展现合规性判断与友好沟通的平衡。
- 科研加速:测试显示,模型可辅助完成“新冠病毒刺突蛋白突变体实验设计”等博士级课题,将复杂科研任务的初期方案生成时间从 72 小时压缩至 3 小时。
- 工业部署:在芯片设计场景中,其长文本处理能力使布线优化任务耗时从 9 小时降至 1.5 小时,功耗降低 12%。

技术普惠
为降低使用门槛,腾讯采取双重策略:
- 成本革命:API 价格体系较前代下降 50%,中小企业可凭千元预算启动专业级 AI 应用开发。
- 工具链优化:提供自动上下文管理接口,开发者无需手动设计 prompt 即可调用长文本推理能力,这在技术文档分析、法律合同审查等场景显著提升开发效率。
行业启示
混元 T1 的发布折射出大模型发展的新方向:
- 架构杂交化:Transformer、Mamba、MoE 等组件的灵活搭配成为主流,2025 年已有 73% 的新发布模型采用混合架构。
- 训练集约化:96.7% 的算力投入强化学习阶段,形成“预训练打基础-RL 精调出性能”的新范式。
- 场景深挖化:从通用对话转向数学/代码/科学等“高壁垒、高价值”垂直领域,预计到 2026 年,专业推理模型市场规模将突破千亿元。
结语
混元 T1 的推出不仅是技术指标的突破,更预示着 AI 产业价值评估体系的转变——当参数规模触及物理极限, “单位算力效能”与“垂直场景穿透力” 将成为新的竞争焦点。正如腾讯云 AI 负责人吴运声老师所言:“未来的 AI 竞赛,不是比谁能建更大的模型,而是比谁能用更聪明的架构解决更实际的问题。”在这场静默的革命中,混元 T1 已为行业树立了新的路标。

来源:腾讯云开发者社区